Apple Unleashes 20 Open-Source Models: Game-Changer or Risky Move?
Apple has recently joined the open-source AI race, making 20 of its models available on HuggingFace (HF). While efforts to make AI more transparent and models widely available have been around for almost a decade, the release of ChatGPT in November 2022 precipitated many new releases. This recent snowball effect, started by OpenAI, has led big tech companies such as Microsoft, Meta and Google to double down on their open-source efforts and commitment to knowledge sharing.
Apple had already published a few of its custom models on HF last year, mostly versions of the StableDiffusion and CLIP models. In April 2024, Apple made another significant stride in the direction of open-source ML, releasing several models from their OpenELM (Open-source Efficient Language Models) collection. This summer, Apple continued its efforts by quietly publishing 20 more models to their HF page, specifically in the CoreML and DCLM collections.
The new collection of models has a strong focus on vision tasks, such as image classification and segmentation. But most of them are multimodal and also include text data in their training or output. Many of these models are versions of the Apple foundation models (a smaller one that runs on device, and a larger server-based one). The specialised models, such as the depth estimation ones, are derived from these foundation models, fine-tuned to a more specific task. The Apple Intelligence framework [1] relies on these models to integrate generative AI in users’ day to day workflow, in which they can easily adapt the models to their needs. So the new open-source Apple models benefit developers, researchers, but also the general population.
This post is focused on the social and ethical impacts of this new release. If you’re also interested in a more technical and comprehensive overview of those models, head over to the bottom of the page!
What are the Benefits of These New Models?
Efficiency in Resource Use
One clear advantage of Apple’s initiative is the efficiency of these models, requiring less memory and power than standard models used for similar tasks. They can all be run locally on Apple devices, on MacOS High Sierra and iPhones on iOS 11 and above [2]. This is obviously more convenient than what developers and researchers are used to; needing a very specific and expensive laptop or cloud platform subscription, having to wait for days for a model to finish training… only to realise it was the wrong data and have to start over 🙂 Maybe with Apple’s new models those days are behind us?
Another perk to mention here is compatibility between models and hardware, Apple ensures a smooth workflow with the use of these models. The CoreML collection also helps convert common libraries such as Pytorch to make them readily usable and compatible with the Apple ecosystem.
Accessibility and Inclusivity
Beyond avoiding the hassle of computational practicalities, this increased efficiency raises the question of accessibility. The bar is lowered in terms of resource requirements, therefore providing easier access to students or smaller researchers to state of the art models. This is a clear advantage for those concerned, but ultimately, the whole AI community benefits from the inclusion of more numerous and diverse minds in this research.
Privacy
As these models are all optimised to run on-device (specifically, Apple devices), it simplifies matters in terms of privacy. This makes it possible to circumvent the search for a secure cloud platform to run models on, which is ultimately a risk. Although many of these platforms (AWS, Google Cloud, Microsoft Azure…) have proven themselves trustworthy to hundreds of thousands of users, there is never a 100% guarantee in terms of privacy and cybersecurity, and even the largest platforms are not immune to attacks (in fact, they might attract them). Running models on-device ensures that they remain available only to their owner, without the intervention of a third party. This also means that the user’s work is not affected by any platform-wide bugs, errors or leaks, avoiding unnecessary interruptions in their work.
Performance – Are These Models any Good?
Apple’s models, specifically the ones that are part of Apple Intelligence, outperform competitors of the same size (such as Microsoft Phi-3-mini), as well as some larger models. Those results originate from tests that aim to evaluate the general capabilities of these models on tasks such as question-answering or mathematic reasoning [3]. Tests conducted by Apple show that the models also achieve high user satisfaction:

But there are reports of other models outperforming Apple’s, such as GPT-4-Turbo which is claimed to perform better in 13% of general capability tests [3].
When it comes to safety however, it seems Apple’s models are indisputably ahead. It deals significantly better with sensitive topics and harmful content than its competitors, including the larger models which are superior in terms of pure performance [3]. This could in part be due to the human feedback incorporated in the training process, which Apple proudly puts forward [4]. In the technical paper, Apple portrays some human evaluation results pertaining to safety and output harmfulness. The Apple foundation models are shown to outperform competing models in most of the tests:

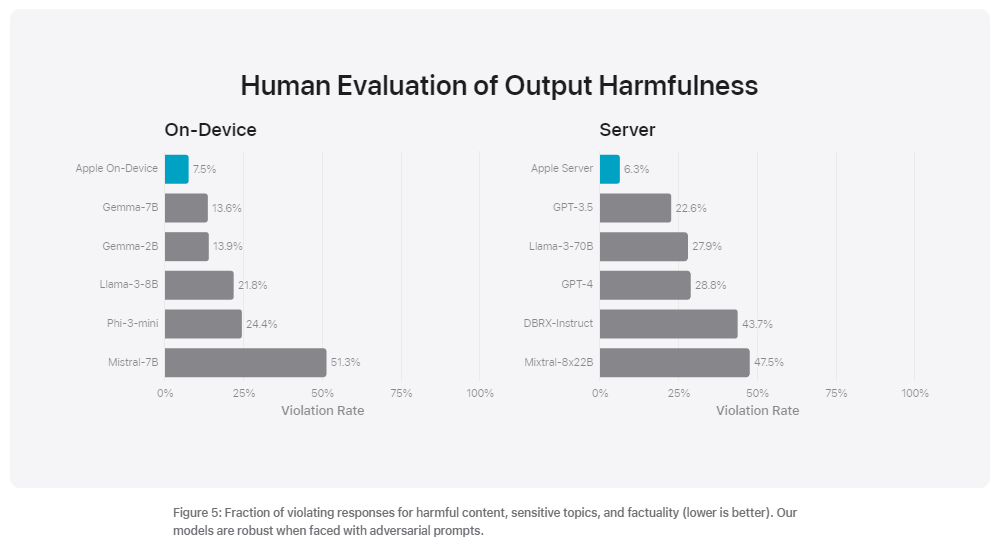
What about the DCLM (DataComp for Language Models) models?
The Apple DCLM models are also promising, as seen through the array of 53 downstream tasks the models are evaluated on. Apple’s models perform similarly to Mistral-7B-v0.3 and Llama 3 8B on the MMLU benchmark [5]. Even more notably, Apple’s model is 40% more efficient than its competitors. The smaller version of the DCLM model (1.4B) also outperforms models of the same size. Apple’s models overall perform as well as the best models out there, except when long texts are involved (because the context window is too small [6]). But for most tasks, this is not an issue, and the resource-efficiency is appealing.
Overall, even if Apple’s models have some limitations, they are definitely giving competitors a run for their money, surpassing or nearing SOTA performance on numerous tasks. However, they have an essential advantage over the competing models when it comes to efficiency. It relies on over 50% less parameters than its competitors (such as LLama) [7], and yet achieves similar performance. This is an essential advantage that, depending on the context, can be significantly more valuable than a slightly higher performance.
General Approval
This initiative follows previous efforts aiming to make high-performance models and their capabilities more accessible to the general population, while also addressing privacy concerns and preserving performance. Apple’s increased open-source efforts are endorsed and enthusiastically approved by HuggingFace’s CEO Clement Delangue, a prominent voice when it comes to open-source technology.
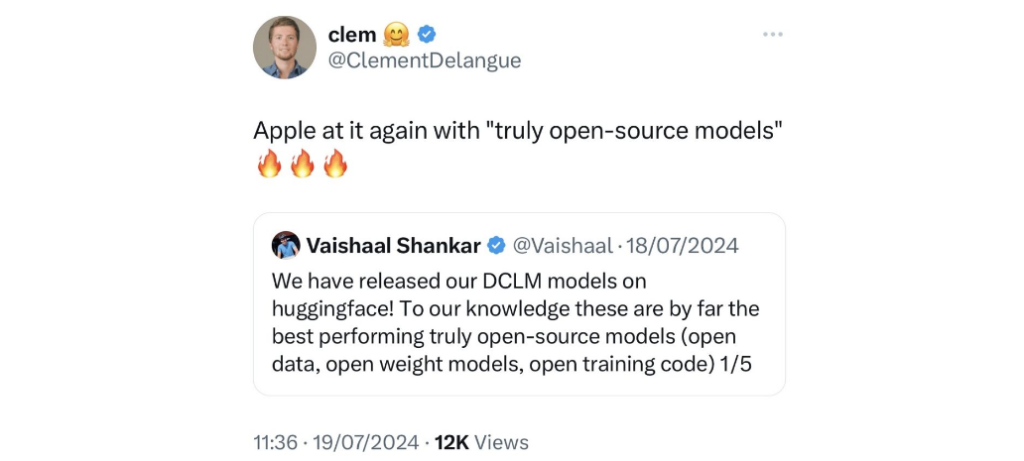
Many news articles and forum threads have already appeared about this, mostly voicing approval and curiosity. However, the reactions are not all enthusiastic.
This seemingly positive initiative raises some concerns…
The Question of Privacy
One of the main benefits of on-device models is privacy. But how private are these models really? They’re only as private and secure as Apple devices are. Apple takes pride in its privacy [8], citing it as one of its core values. The company has even been somewhat of a pioneer in terms of certain privacy measures [9]. However, Apple is not immune to security breaches, as seen with a recently found vulnerability in Apple’s Safari search engine, which was being exploited by hackers. And there have been other similar instances in the past. It should be noted though, that Apple has a very good track record in addressing vulnerabilities in a timely manner with effective system updates.
Aside from system security and privacy vulnerabilities, concerns have been raised about the data Apple collects from its users. As required by law, the collected data is detailed in the terms and services that accompany every piece of Apple hardware and software. While they’re legally in the clear, let’s face it, nobody reads the terms and services, and many could be ‘agreeing’ to things they don’t really agree with. And even when these documents are read by the user, when it’s a matter of dozens of pages of fine print, it is not difficult for companies to slip in pretty much whatever they want. But of course, this does not mean Apple is doing anything wrong, simply that caution is advisable when it comes to privacy.
Elon Musk for instance has made his disdain clear on X, claiming that Apple is attempting to spy on its users and threatened to ban Apple products from his companies.
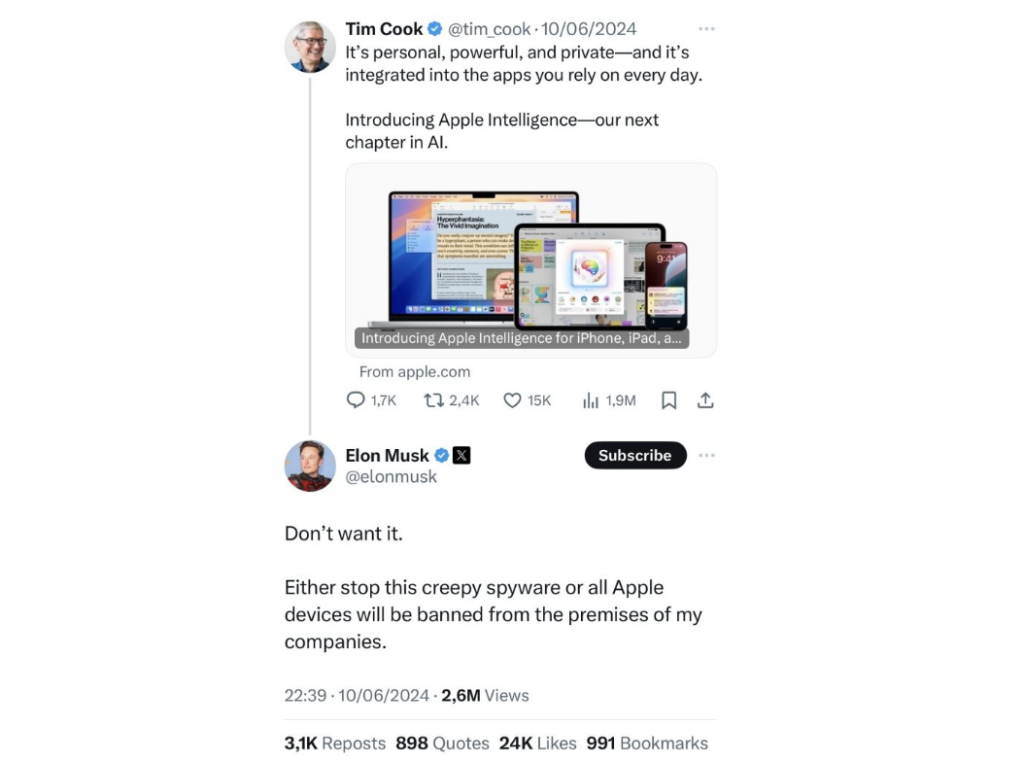
But the real question here is: those models that can be fine-tuned and ran on Apple devices… Does Apple have access to them? According to their terms and services, local data, models and code should not fall within the scope of data that Apple needs to access. However, this does not mean Apple cannot access this data. We’ve all seen those articles appearing every once in a while: “Is Apple reading your messages?”, “Is your iPhone listening to you?”… While this data is encrypted to protect user data from outside attacks, Apple does have access to the encryption keys and is able to decrypt data when absolutely necessary (in case of a major security threat for instance) [10] . So yes, Apple could access this data but they claim not to, barring extenuating circumstances. Of course, our messages mostly are not of much interest to Apple, so there is no reason to doubt these claims. However, when it comes to cutting-edge ML research, the stakes are higher. So ultimately it comes down to whether you trust Apple to act in line with their promises and proclaimed values at least as much as you trust the alternatives (AWS, etc.), and to how important a guarantee of total privacy is when it comes to your models.
Are We Increasingly Trapped in the Apple Ecosystem?
Apple is already widely criticised for ‘trapping’ its users by making it increasingly difficult to migrate data and accounts to other platforms, such as android, especially once you’re used to using Apple and rely on various features of the ecosystem.
But… what is the Apple ecosystem?
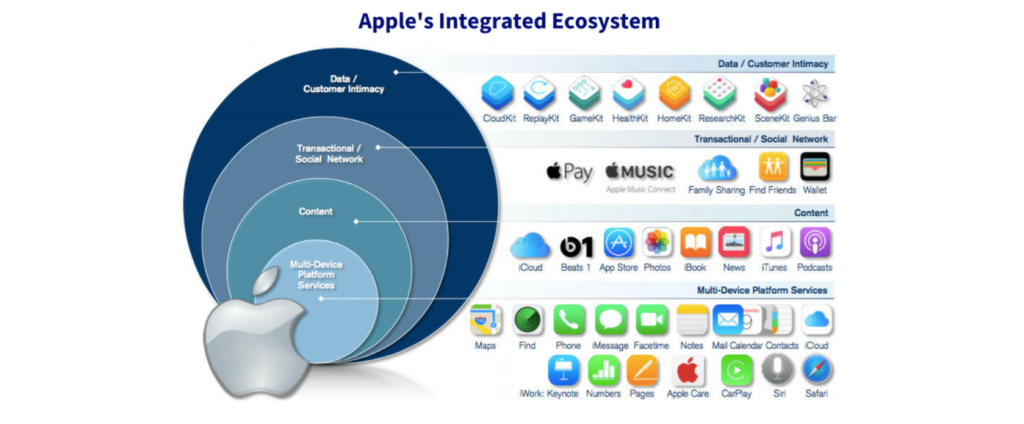
Image source: Interana
{kind=link}
It is the set of features that connect the user, their data and the different Apple devices they use, in order to provide a very easy and seamless experience. The iCloud and AppleID ensure compatibility between the user’s data and accounts, making the transition from one Apple device to another almost intangible. Other features, such as the Keychain or AirDrop, target more specific operations that provide the same continuity across devices and applications, improving user experience. The Apple ecosystem is so effective and simple that it’s easy to quickly end up fully relying on it. This means that outside of the ‘Apple world’, you might find yourself logged out of all your accounts, without usernames or passwords, without your messages or contacts, without bank account access (maybe don’t forget about physical credit cards yet…), and possibly even without the playlist you carefully put together for moments just like this one. Ouch. Obviously, continuing to use Apple products is the only solution that is not terribly inconvenient. Well done Apple, as far as customer retention strategies go, this is a good one.
With the publication of these open-source models tailor-made for use on Apple devices, not only are the user’s personal lives and workflows dependent on this ecosystem, developer’s professional lives could get them sucked into it even more. But is this really a problem? No, as long as you remain loyal to Apple it will likely be extremely convenient. But Apple will not make it easy to transfer those models away from their devices. And perhaps this is their right, they provide a high-quality experience and get loyalty in return. What’s more, users are consenting individuals. So the question is, are they aware of the extent to which they will end up relying on Apple? Are they sufficiently informed about the drawbacks of withdrawing their consent? Should there even be drawbacks to consent withdrawal? Ultimately, these are ethical questions beyond the scope of this post… But these questions should be considered by those thinking about venturing into the Apple ecosystem, lured by those shiny new models.
“Ethically-Sourced Training Data”?
Another concern recently raised about Apple’s new open-source models is the data they used to train those models. Apple claims that for training those models they used licensed data and publicly available data, collected with the AppleBot [11] web-crawler. Publishers allegedly have the option to opt out if they do not want their data to be used. Apple also firmly states that it does not use its users’ personal data for training purposes [4], as it would infringe upon their promised privacy. There has not been any information suggesting that these statements are not true. However, there are criticisms related to the use of the ‘publicly available’ data scraped from the internet, putting the morality of this approach into question. This practice has become quite common among AI companies, some of which have faced lawsuits [12] for their data-gathering methods. But isn’t public data intended to be viewed and used freely? To some extent, yes. But this does not give individuals that have content on a website that is not theirs any choice in the matter. What’s more, most of the time the owners of the data have not given consent for their data to be used for such purposes. For instance, an open-access news outlet provides free access for its content to be read and cited, but this does not mean the writers and owners want their data to be used to train an LLM, which could adopt part of their ideas and style as its own, or in this case, Apple’s property. It comes down to large companies profiting off human work without their consent, without any credit and without remuneration.
Furthermore, Apple (as well as Anthropic and Nvidia) has been found to use a dataset consisting of subtitles of over 170 000 YouTube videos [13]. Again, the data is public, but using it in this way is not included in the YouTube terms of service, meaning that users did not give consent. And YouTube has been around for a while (since 2005), so it’s not like users who posted videos could have or should have anticipated their data to be used with the purpose of training large ML models.
To fend off potential criticisms about their lack of transparency, Apple has published a 30 page technical paper, detailing its training approach, from data to testing, including a section dedicated to ‘Responsible AI’ [14]. While this is undoubtedly a positive initiative, it does not clear up all doubts about the data used to train these models. The datasets are not explicitly cited, and all Apple really says about this is that they use “a diverse and high quality data mixture”. Hm.
The paper was published but some parts are vague; clearly Apple would not publish any self-incriminating information. So is this paper just Apple hiding its secrets in plain sight? Or are people eternally suspicious and unsatisfied by Apple’s positive contributions to the AI community and consumer experience?
Conclusion
Apple’s new open-source ML models bear many advantages, primarily due to their notable efficiency. This addresses the usual time and resource limitations of increasingly large models, which have become a constant concern among researchers. As a result, state-of the art ML models are accessible to the general population, and accessible to smaller researchers who do not have access to the computational resources traditionally needed for these models. Furthermore, the efficiency of the models allows them to be ran on Apple devices, circumventing the need for cloud-based environments. From a privacy viewpoint, this is also an interesting advantage.
Although Apple has been staying quiet about those models, this release has definitely made waves and people are talking about it. Overall, it is met with approval but there are some legitimate questions about Apple’s intentions and their approach to selecting data and training these models. Does Apple truly want to bring a positive contribution to the Open-source community, or are they just following the trend and trying to avoid falling behind their competitors? Could this be a strategic move to improve their customer retention by tightening the grip the Apple ecosystem has on users? More importantly, does running these models on-device truly guarantee total privacy, or might Apple have access to models fine-tuned by users? That would imply access to valuable research and private intellectual property.
All in all, there is no incriminating evidence out there pertaining to Apple’s big move. There are however multiple irrefutable benefits to their new releases, so perhaps they should be given the benefit of the doubt on this one. Of course, when it comes to privacy and data protection, we must remain critical and alert. But for now, let’s go try out these cool new models 🙂
Overview of the New Models – 6 Categories
1. DCLM – DataComp for Language Models
DCLM is a joint initiative between 23 institutions, including Apple, aiming to advance research on improvement of LLMs by providing an experimental testbed geared towards dataset optimisation. Their approach is novel, in the sense that they shift the focus from finding the best model to finding the best training data. A large corpus (240T tokens) of raw data is provided to participants, who can then experiment with various data processing and filtering techniques, with the goal of creating datasets that improve LLM performance. 53 downstream evaluations are provided to test the proposed datasets. The benchmark includes different model scales, ranging from 412M to 7B parameters, making this initiative inclusive and accessible regardless of available resources. The DCLM paper provides a nice visual representation of this workflow:
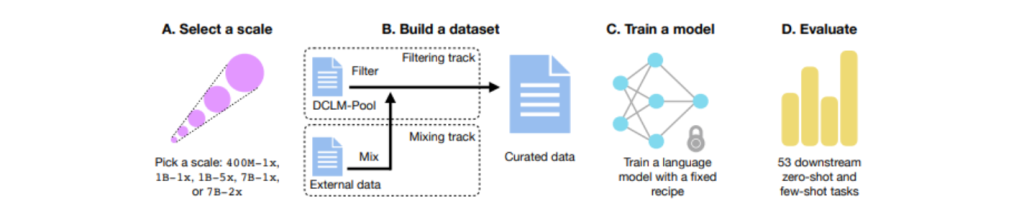
On HF, Apple published 4 models in this category:
- DCLM-Baseline-7B: trained on the baseline DCLM dataset
- DCLM-Baseline-7B-8k: similar adapted to support a larger context window (around 4 times larger)
- DCLM-1B-v0: also a baseline, but smaller
- DCLM-IT-7B: trained on DCLM baseline dataset but further fine-tuned by Apple
Apple also published 2 DCLM datasets:
- A baseline dataset for general purposes
- A second baseline, in parquet format, more space efficient and optimised for large scale data processing
Read more here:
2. DFN – Data Filtering Networks
The original CLIP (Contrastive Language-Image Pre-training) model was designed by OpenAI to jointly learn from images and text data in order to be able to connect various images with their textual descriptions. DFNs are networks that can be used to filter large amounts of raw data. The two new open-source CLIP models released by Apple in this category rely on such DFNs for image-to-text and zero-shot image classification tasks.
Here are most recent additions to this collection of models:
- DFN2B-CLIP-ViT-L-14-39B: trained on 2B images that were filtered from a larger pool of uncurated image-text pairs
- DFN-public: trained on three datasets of image-text pairs: Conceptual Captions 12M, Conceptual Captions 3M, and Shutterstock 15M’
3. DepthAnything
This is a family of depth estimation models, similar to but more efficient (10 times faster) than Stable Diffusion. The models rely on labeled synthetic data (600k images) and 62 million real but unlabeled images. This addresses some limitations related to availability of large amounts of labeled real data, which is often an obstacle in the way of high performance. Notably, DepthAnything models achieve state-of-the-art (SOTA) performance on tasks related to relative as well as absolute depth estimation.
The two models made available by Apple are:
- coreml-depth-anything-small
- coreml-depth-anything-v2-small
4. FastViT
Two variants of FastViT (Fast Hybrid Vision Transformer) have also been made public, focusing on tasks such as image classification, detection or segmentation. These models are designed to very efficiently process and analyse visual data. They achieve this through combining Transformer performance with the speed and efficiency associated with CNNs. FastViT models rely on structural reparameterisation techniques, which optimise the structure of the model based on the phase of the training/inference process. This allows for sufficient complexity during training, and increased efficiency during inference. Sure enough, this method achieves a SOTA latency-accuracy trade-off.
The two models in this category are:
- coreml-FastViT-T8: Image classification, feature backbone (more efficient, good for mobile use)
- coreml-FastViT-MA36: Image classification (11 times larger and more complex)
Tic-CLIP
The TiC-CLIP models recently provided by Apple are specialized versions of CLIP models that have been adapted for Time-Continual Learning (TiC). The goal of this approach is to address the difficulty of keeping large vision models updated, while avoiding frequent retraining from scratch, which can be excessively expensive, both in terms of computational resources and time. TiC methods allow for continuous learning, which means that the model constantly improves and adapts to new data. This ensures that the accuracy and reliability of those vision models does not decrease with time.
Apple provides one dataset: TiC-DataComp (part of DataComp, optimised for TiC)
And 6 models:
- TiC-CLIP-basic-cumulative
- TiC-CLIP-basic-oracle
- TiC-CLIP-basic-sequential
- TiC-CLIP-bestpool-cumulative
- TiC-CLIP-bestpool-oracle
- TiC-CLIP-bestpool-sequential
The models differ in their training strategy and learning approach.
Training strategy:
- Basic: standard, all data treated equally
- Bestpool: most relevant or higher quality data is used
Learning approach:
- Cumulative: the model is continually trained on new data while incorporating all previous data. The model’s knowledge therefore increases over time, constantly improving.
- Oracle: the model is assumed to have access to the optimal data at each point in time. The learnt patterns represent an optimal decision-making process, a perfect hindsight. This represents the ideal scenario, which is often used as a benchmark to evaluate other strategies.
- Sequential: during training, the model is updated with new data without revisiting older data. This aims to simulate a real-world scenario where only the most recent data is available for training, so the model must adapt to changes over time without access to past information.
CoreML Gallery Models
Lastly, three more models, which can all be ran locally on Apple devices, are added to Apple’s ‘Gallery Models’ collection on HF:
- coreml-detr-semantic-segmentation: based on the detection transformer, applicable to medical imaging, autonomous driving, etc.
- coreml-YOLOv3: designed for one-shot real-time object detection, can quickly and accurately detect objects in images or videos
- coreml-resnet-50: a deep CNN with 50 layers for image classification, useful for object or facial recognition for example
References
[1] https://www.apple.com/apple-intelligence/
[2] https://aibusiness.com/nlp/apple-releases-20-new-open-source-ai-models
[4] https://machinelearning.apple.com/research/introducing-apple-foundation-models
[5] https://arxiv.org/abs/2406.11794
[8] https://www.apple.com/privacy/
[9] https://www.wired.com/story/apple-privacy-data-collection/
[11] https://support.apple.com/en-us/119829
[12] https://edition.cnn.com/2024/06/13/tech/apple-ai-data-openai-artificial-intelligence/index.html